说明:本报告基于 ChatGPT 的 DeepResearch 深度研究撰写
审核+校验:Weber
I. 执行摘要
1.1 Gemini 3 的战略定位与核心技术概述
Google Gemini 3 的发布标志着大型语言模型(LLM)能力向原生多模态推理和高级智能体(Agentic)工作流迈出了重要一步。模型于 2025 年 11 月开始采取”静默部署”策略,在未进行传统高调宣传的情况下,将其性能逐步推向真实世界环境 ¹。这一策略旨在强调模型的实际表现而非营销炒作,是 Google 努力恢复开发者社区信心的重要举措 ¹。

Gemini 3 Pro 在多个核心基准上确立了新的技术标杆:
- 原生多模态领导者: 在评估集成理解和推理能力的 MMMU-Pro 基准上,Gemini 3 Pro 取得了 81.0% 的分数,领先竞争对手 GPT-5.1(76.0%)多达 5 个百分点 ²。
- Agentic 智能体核心: 在 Agentic 编码任务的 SWE-Bench Verified 基准上,Gemini 3 Pro 的单次尝试成功率达到 76.2%³。
- 深层思维突破: 专为最困难推理任务设计的 Gemini 3 Deep Think 模式,在解决需要代码执行的新颖挑战(如 ARC-AGI-2)上,取得了 45.1% 的突破性得分 ⁴。
1.2 关键突破与市场地位
Deep Think 模式在复杂推理基准(如 Humanity’s Last Exam 达 41.0% ⁴)上的出色表现,表明该模型在泛化能力和抽象推理方面正向通用人工智能(AGI)的能力迈进。Gemini 3 的市场定位是面向需要处理复杂、多源数据的企业级 Agentic 平台的核心智能体。
1.3 主要局限与风险提示

尽管取得了显著进步,Gemini 3 仍面临关键局限:
- 长上下文稳定性挑战: 尽管模型具备业界领先的 1M 令牌上下文窗口容量 ⁵,但在极端长上下文的点测试(MRCR v2, 1M pointwise)中,信息检索性能显著衰减至 26.3% ³。
- 网络安全预警: 官方《前沿安全框架报告》(FSF)指出,Gemini 3 Pro 在网络安全领域已达到早期预警阈值 ⁶,这要求企业在部署其 Agentic 工作流时,必须采取严格的风险缓解措施。
- 情感智能不足: 社区用户反馈,相比竞争对手,Gemini 在处理情感或生成自然对话时显得”最不自然” ⁷。
II. Gemini 3 模型的重大突破与静默部署
2.1 部署方式与初期用户反馈
Gemini 3 的推出采用了与过去版本大为不同的”静默部署”策略。在技术界对 Gemini 生态系统长期存在的争议、隐私诉讼和图像生成失误保持高度关注的背景下 ¹,Google 于 2025 年 11 月在没有任何高调发布会或官方博客的情况下,静悄悄地开始在真实环境中部署 Gemini 3 ¹。
这种务实策略在开发者社区内获得了积极的反响。模型首先在 Canvas 移动端等环境中浮现,用户注意到工具开始产生比运行 Gemini 2.5 Pro 的桌面版本更高质量的结果 ¹。这种差异化性能对比很快在开发者论坛中传播,用户普遍的反馈是模型的能力得到了”戏剧性”的提升。一位 Reddit 用户总结了这种感受:”一切都是真实的,并有证据支持。这不是炒作。” ¹。
对于习惯了过度承诺和失望的开发者群体而言,Google 此次选择静默部署、强调实际性能而非市场宣传,被视为一种战略上的转变,意味着公司将重心从速度竞赛转向了可靠性与稳定性。对于正在寻求稳定、可信赖 AI 解决方案的企业用户来说,这种务实的态度有助于降低部署先进模型的风险。
2.2 Deep Think 模式:迈向通用智能(AGI)的信号
Gemini 3 Deep Think 模式代表了 Google 在提高模型推理复杂性方面所做的努力。Deep Think 旨在挑战并解决那些需要超越传统模式的抽象推理和规划能力的问题 ⁴。

该模式的关键性能体现在以下严苛的推理基准上:
- Humanity’s Last Exam: 在不使用工具的情况下,Deep Think 取得了 41.0% 的得分 ⁴。
- GPQA Diamond: 在此基准上的得分为 93.8% ⁴。
- ARC-AGI-2: 在需要代码执行的 ARC Prize Verified 挑战中,取得了前所未有的 45.1% ⁴。
Deep Think 在 ARC-AGI-2 上的高得分具有重大意义。ARC-AGI 评估的是模型解决未见过的、需要代码执行的抽象问题的能力。45.1% 的得分证实了 Deep Think 模式具备强大的泛化和抽象规划能力,意味着它可以将概念从训练数据泛化到新颖的领域,而不仅仅是记忆和复述。这种能力是判断模型是否具备 L3 或 L4 级别自主 AI Agent 能力的关键指标。
III. 核心能力分析:多模态与超长上下文
3.1 原生多模态理解与推理的结构性优势
Gemini 3 Pro 是一款原生的多模态模型,这意味着它能同时理解和推理不同的数据类型,如文本、图像和视频 ²。这种集成能力使其在多模态基准测试中占据结构性优势。

- MMMU-Pro 领先性: MMMU-Pro 是衡量模型集成多模态理解和推理的关键基准。Gemini 3 Pro 在此基准上得分 81.0%,领先 GPT-5.1(76.0%)达 5 个百分点 ²。这表明 Gemini 3 在处理复杂的跨模态输入时,能更有效地进行深度推理。
- 专业多模态应用: 模型的优势已延伸至专业领域的数据分析,而非仅限于消费级应用。例如,在复杂图表信息合成(CharXiv Reasoning)上,模型取得了 81.4% 的高分;在屏幕理解(ScreenSpot-Pro)上,得分也达到了 72.7% ³。这些表现意味着模型能够从复杂的、专业化的视觉数据(如金融图表、SaaS 界面截图)中准确提取并合成信息。
- 多语言能力: Gemini 3 Pro 在多语言问答(MMMLU)基准上以 91.8% 的得分略微领先 GPT-5.1(91.0%),并在跨 100 种语言和文化的常识推理(Global PIQA)上取得 93.4% 的得分 ²。
上述 CharXiv Reasoning 和 ScreenSpot-Pro 的高分表明,Gemini 3 的多模态能力已经从简单的图像描述升级为企业级的分析和自动化工具。其屏幕理解能力直接支撑了计算机使用智能体(computer use agents)的性能提升,这对推进 Agentic 工作流在 IT 运营、数据分析和企业自动化等场景中的落地至关重要 ⁸。
3.2 长上下文处理能力评估:高容量与稳定性挑战并存
Gemini 3 Pro 提供了业界领先的 1M 令牌上下文窗口,使得模型理论上能够一次性摄入和处理完整的代码库、企业级长文档或大量的历史对话记录 ⁵。这一容量被视为实现复杂、长周期 Agentic 任务的基础。
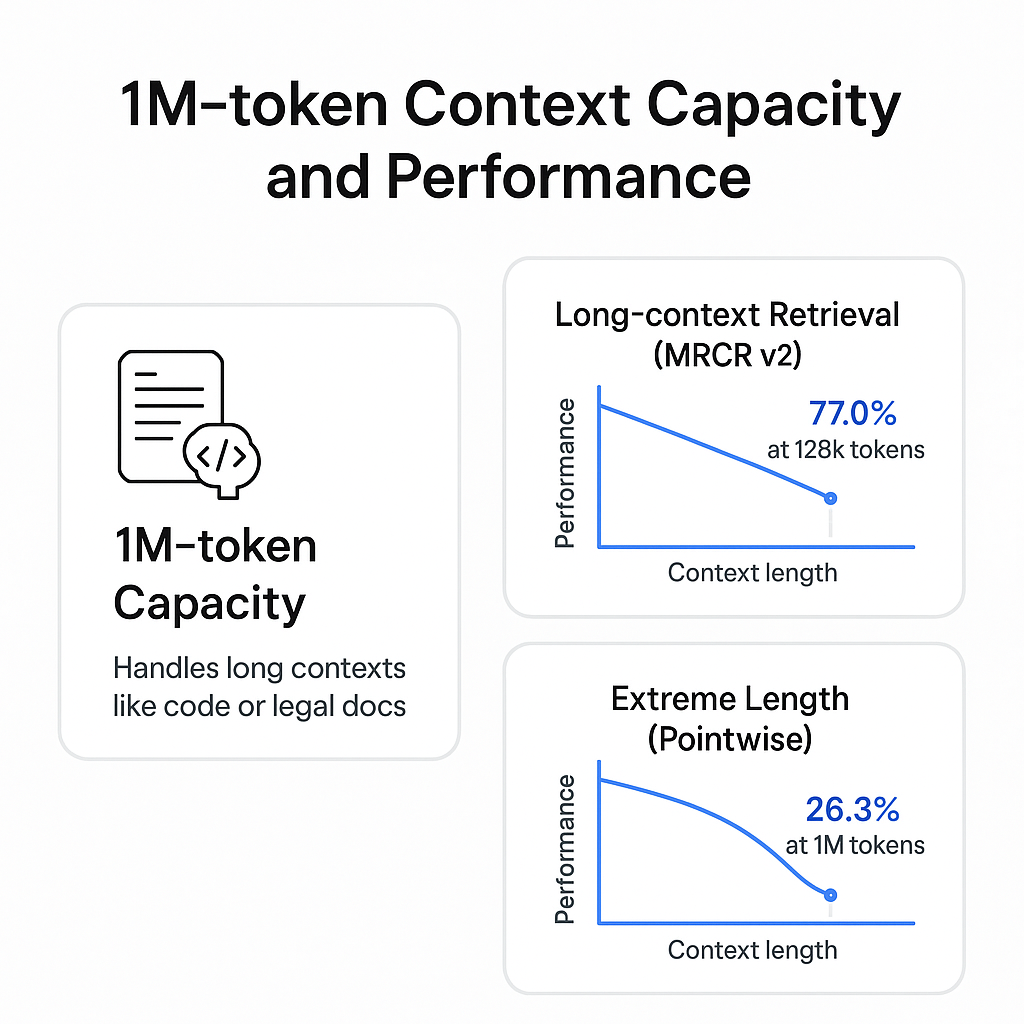
然而,对长上下文性能的评估揭示了容量与实际可靠性之间的差异:
- 1M 令牌容量: 模型在处理长上下文(如代码库或大型法律文档)时表现出超越前代模型的性能 ⁵。
- 长上下文检索性能 (MRCR v2): 在多段落内容检索(MRCR v2)基准上,模型在处理 128k 令牌的平均性能达到 77.0% ³。
- 极端长上下文的衰减: 当测试上下文长度延伸至 1M 令牌,并采用极端点测试(pointwise,即”大海捞针”测试)时,Gemini 3 Pro 的信息检索准确率显著下降至 26.3% ³。
这一数据显示了长上下文的“长尾效应”,即模型的整体容量虽然巨大,但在处理最长上下文时,对任意位置信息的精确检索稳定性仍然是瓶颈。这意味着企业在利用 1M 令牌窗口处理大型代码库或法律文档时,不能完全依赖模型在任意位置的精确检索,需要通过额外的分块、摘要和验证策略来缓解信息丢失的风险。
关键数据表格 I:Gemini 3 Pro 核心能力基准 (官方数据)
| 基准名称 | 能力侧重 | Gemini 3 Pro 评分 | 对比模型 (GPT-5.1) | 数据来源 |
|---|---|---|---|---|
| MMMU-Pro | 多模态理解与推理 | 81.0% | 76.0% | ² |
| MMMLU | 多语言问答 | 91.8% | 91.0% | ² |
| CharXiv Reasoning | 复杂图表信息合成 | 81.4% | N/A | ³ |
| SWE-Bench Verified | Agentic 编码(单次尝试) | 76.2% | N/A | ³ |
| MRCR v2 (128k average) | 长上下文性能(平均) | 77.0% | N/A | ³ |
| MRCR v2 (1M pointwise) | 极端长上下文性能(点测) | 26.3% | N/A | ³ |
IV. 深度专题:AI 编码与智能体工作流的表现
Gemini 3 Pro 在 AI 编码领域的能力提升是其最受开发者关注的亮点之一。该模型不仅在传统代码生成上超越了前代版本 Gemini 2.5 Pro,更是在 Agentic 智能体工作流中展现出强大的规划和执行能力 ⁶。
4.1 Agentic Coding 能力的量化评估

Gemini 3 Pro 的 Agentic 编码能力通过专业基准得以量化验证:
- SWE-Bench 表现: 在解决现实世界代码库中的错误和问题所需的 Agentic 编码基准 SWE-Bench Verified 上,Gemini 3 Pro 获得了 76.2% 的得分 ³。
- Terminal-Bench 表现: Terminal-Bench 2.0 专门测试模型通过终端操作计算机和使用工具的能力。Gemini 3 Pro 在此基准上得分为 54.2% ⁸。这一分数直接反映了模型在自主执行开发任务中的效能。
Gemini 3 Pro 已被定位为下一代 Agentic 编码模型的基础智能。它能够处理跨越整个代码库的复杂、长周期任务,并保持上下文以支持多文件重构、调试会话和功能实现 ⁸。这种能力使其成为企业进行遗留代码迁移和自动化软件测试的”力量倍增器” ⁵。

该模型已集成到 Google Antigravity(新的 Agentic 开发平台)、Gemini CLI、Android Studio,以及 Cursor、GitHub、JetBrains 等主流开发环境中 ⁸。例如,Google Antigravity 允许开发者充当架构师,与智能 Agent 协作,由 Agent 在编辑器、终端和浏览器中自主规划和执行复杂的软件任务 ⁶。
4.2 实际开发体验:“意图领会”与零样本成功率
来自开发者和行业专家的实际测试反馈,揭示了 Gemini 3 Pro 在现实编码任务中的高阶协作能力:
- 零样本突破: 有开发者反馈,他们能够通过单个提示(zero-shot prompt)生成一个功能完整的 3D 坦克游戏,这是他们在使用其他模型时从未实现过的 ⁹。这证明了其在复杂场景下强大的零样本解决能力。
- 高阶协作能力与”意图领会”: 在与 GPT-5.1 和 Claude Sonnet 4.5 的真实编码任务对比中,Gemini 3 Pro 表现出一种”意图领会”的能力 ¹⁰。在创建网页版”拇指大战”游戏的任务中,作者最初只提到了”屏幕点击”控制,但 Gemini 3 Pro 的第一个版本主动添加了键盘控制选项 ¹⁰。
- 设计优化: 在后续迭代中,模型不仅仅是执行指令,还对用户请求进行了优化和扩展。例如,当要求使游戏场看起来更真实时,Gemini 3 Pro 添加了 “CSS 视角倾斜”来增加深度 ¹⁰。当要求让攻击更具戏剧性时,模型实现了”整个摄像机在重击落地时晃动”的动画效果 ¹⁰。这种能力超越了简单的代码补全,使其成为真正的软件设计协作者。
- 长程上下文保留: 在多轮复杂的 3D 编码迭代过程中,Gemini 3 Pro 始终保持强大的上下文记忆,从未要求作者重新开始或提醒先前的工作,有效提高了长周期项目中的开发效率 ¹⁰。
这种能够预测用户未明确提出的需求、主动优化设计和保持长期任务上下文的能力,表明其 Agentic 模块能够结合上下文、目标平台和用户潜在意图进行高级推理和决策,显著提高开发效率并减少代码审查中的返工 ¹³。
关键数据表格 II:Agentic Coding 性能对比
| 模型 | SWE-Bench Verified (Agentic 编码) | Terminal-Bench 2.0 (工具使用) | 实时编码任务反馈 (TechRadar 测试) | 数据来源 |
|---|---|---|---|---|
| Gemini 3 Pro | 76.2% | 54.2% | 意图领会强,上下文保留优秀,主动优化用户请求 | ³ |
| GPT-5.1 | N/A | N/A | 表现次于 Gemini 3 Pro,较少主动优化 | ¹⁰ |
| Claude Sonnet 4.5 | N/A | N/A | 表现次于 Gemini 3 Pro,长期一致性可能更优 | ¹³ |
V. 顶尖主流模型竞争格局对比
2025 年的顶尖 LLM 竞争格局已经高度分化,模型不再是纯粹的通用文本生成器,而是根据其架构优势和目标市场(多模态、情感智能、长上下文、成本效益)进行差异化竞争。
5.1 与 GPT-5.1 及 Claude 4.5 的直接竞争分析

- 多模态与推理: Gemini 3 Pro 凭借其原生多模态架构,在 MMMU-Pro 上领先 GPT-5.1 5 个百分点 ²,确立了其在跨模态推理上的领导地位。
- 长期记忆与一致性: Anthropic 的 Claude 4.5 采用了”Frontier”架构,其优势不在于原始参数量(Gemini 3 Pro 约为 1 万亿参数),而在于在长周期项目中的一致性。有企业用户测试反馈,在长达 6 周的合同审查任务中,Claude 4.5 能够始终记住细微的细节,如关于延迟付款的条款 ¹²。这表明 Claude 4.5 在处理持续、复杂的企业级任务时,可能在长期记忆的可靠性上优于 Gemini 3。
- 商业模式: Gemini 3 Pro 为吸引更广泛的开发者和小型团队,提供了有限的免费层级,允许进行概念验证 ¹²。相比之下,Claude 4.5 主要面向企业用户,采用 $20/月/用户的付费订阅制 ¹²。
5.2 与 Grok 4.1 的差异化竞争:情感与事实的权衡
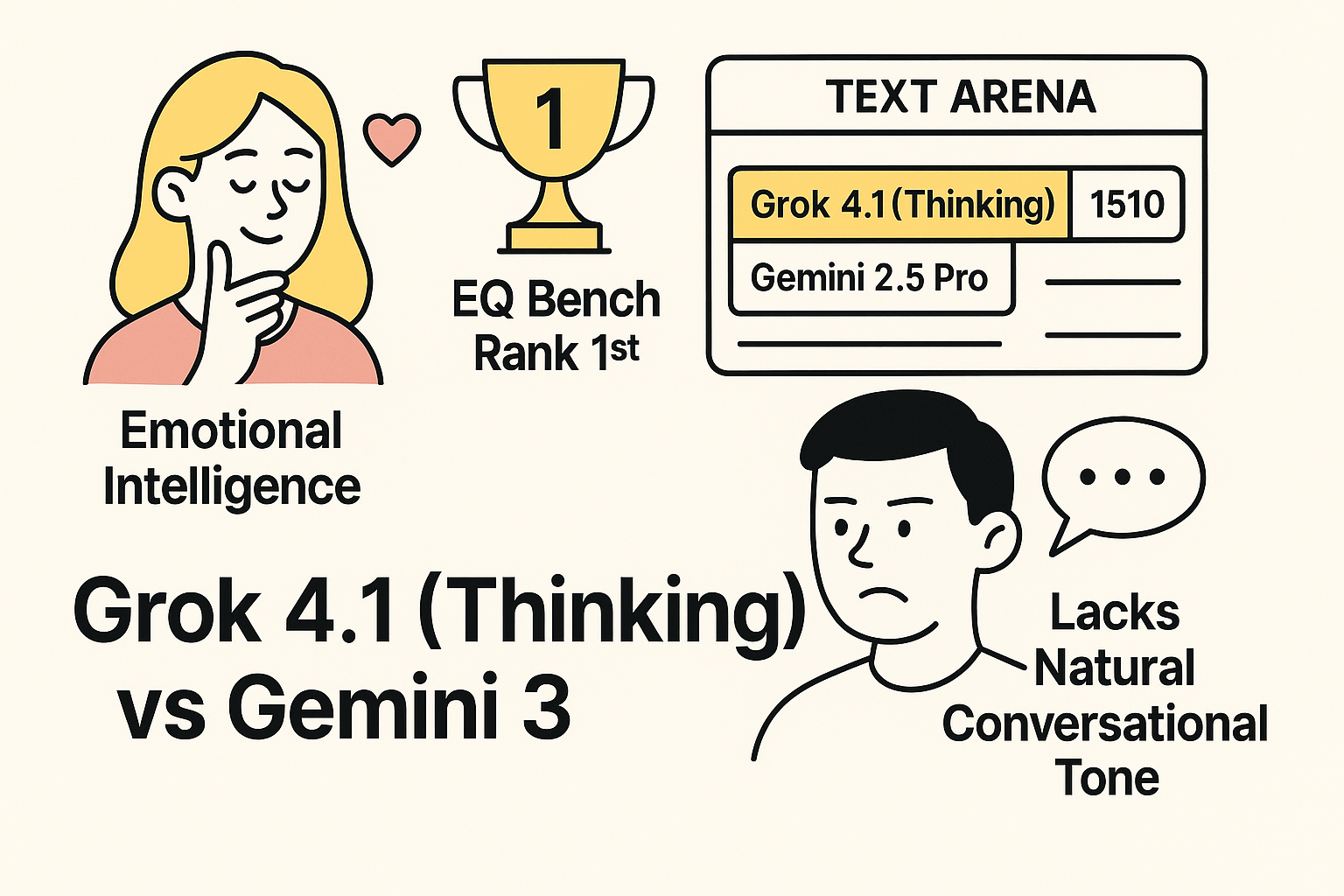
xAI 的 Grok 4.1 及其 Grok 4.1 Thinking 版本,采取了与 Gemini 截然不同的竞争路径,重点关注用户体验和情感交互。
- 情感智能的领导者: Grok 4.1 (Thinking) 在 LLM 评判的 EQ Bench(情感智能)基准上排名第一 ¹³。Grok 4.1 强调其在创造性、情感和协作互动中表现出色,对细微意图的感知更加敏锐,且具有连贯的个性 ¹³。
- 文本竞技场表现: Grok 4.1 (Thinking) 在 LMArena 文本竞技场专家排行榜上以 1510 的得分位居榜首,成功超越了此前的领导者 Gemini 2.5 Pro ¹³。
- Gemini 3 的情商短板: 用户反馈表明,尽管 Gemini 在科学推理上表现出色,但在处理情感或需要自然、引人入胜的对话时,它显得”最不自然” ⁸。这反映了 Google 对安全和事实性的严格偏好,可能导致其在需要高度情商的场景中缺乏竞争力。
Grok 4.1 在情感智能上的领先,标志着模型竞争已从纯粹的逻辑和硬指标,扩展到用户交互质量。对于面向客户服务的 AI 或创意写作 Agent 而言,Gemini 3 在情感自然度上的不足可能是一个明显的缺陷。
5.3 国产模型 Kimi-K2-thinking 与 Minimax M2 的定位
在中国市场,以 Kimi-K2-thinking 和 Minimax M2 为代表的模型,凭借其在长上下文处理和成本效益方面的优势,形成了重要的竞争力量。
- Kimi-K2-thinking: 该模型拥有 262.1K 令牌上下文窗口,并提供先进的推理和结构化数据生成能力 ¹⁶。虽然一些社区观点认为其性能(作为 INT4 量化模型)不可能显著超越 Claude 4.5 或 GPT-5,但在中文推理任务和长上下文处理上仍被认为是功能强大的模型,大致与 GLM 4.6 处于同等水平(Kimi K2 在推理上更强,GLM 4.6 在编码上更优) ¹⁷。
- Minimax M2: 这款模型具有 204.8K 令牌上下文,其主要竞争优势在于极高的成本效益(输入代币 $0.26/M,输出代币 $1.02/M) ¹⁶。尽管其参数量较小(10B/230B),但在特定场景下仍被认为性能强劲,定位为经济高效的高性能选择 ¹⁷。
关键数据表格 III:顶尖主流模型竞争对比(2025 年 Q4 状态)
| 模型 | 核心架构/规模 | 主要竞争优势 | 已知相对短板 | 关键指标/排名 | 数据来源 |
|---|---|---|---|---|---|
| Gemini 3 Pro | 1 万亿参数,原生多模态 | 原生多模态集成,Agentic Coding,Deep Think 复杂推理 | 极端长上下文稳定性,情感智能不足 | MMMU-Pro 81.0%,Terminal-Bench 54.2% | ² |
| GPT-5.1 | Frontier(未公开参数) | 文本生成精度,上下文理解(持续优化) | 多模态集成效果略逊于 Gemini 3 | MMMU-Pro 76.0%,Creative Writing v3 排名第一(早期版) | ² |
| Claude 4.5 | Frontier 架构 | 长期记忆一致性,企业级支持 | 编码能力和零样本推理可能略逊于 Gemini 3 Pro | 长期合同审查细节保持性强 | ¹³ |
| Grok 4.1 (Thinking) | 专注文本/对话 | 情感智能 (EQ),创造性写作,对话体验 | 科学/逻辑硬指标对比未公开,多模态能力未知 | EQ Bench 排名第一 | ¹³ |
| Kimi-K2-thinking | INT4 量化 | 长上下文 (262.1K),中文推理,性价比 | 参数规模限制,通用能力可能受限 | 上下文 262.1K 令牌 | ¹⁶ |
VI. 客观评估:局限性、用户体验及安全风险
对任何前沿 AI 模型的客观评估必须同时涵盖其性能优势和固有的局限性及安全风险。
6.1 官方安全框架(FSF)下的风险与局限性解读
Google DeepMind 发布的《Gemini 3 Pro 前沿安全框架报告》主要聚焦于模型在四大前沿风险领域(CBRN、网络安全、ML R&D 和有害操纵)的评估。总体而言,Gemini 3 Pro 并未达到任何预先定义的”关键能力级别”(CCL),因此被判定为可接受部署 ⁷。
然而,报告揭示了以下关键的风险点和局限性:
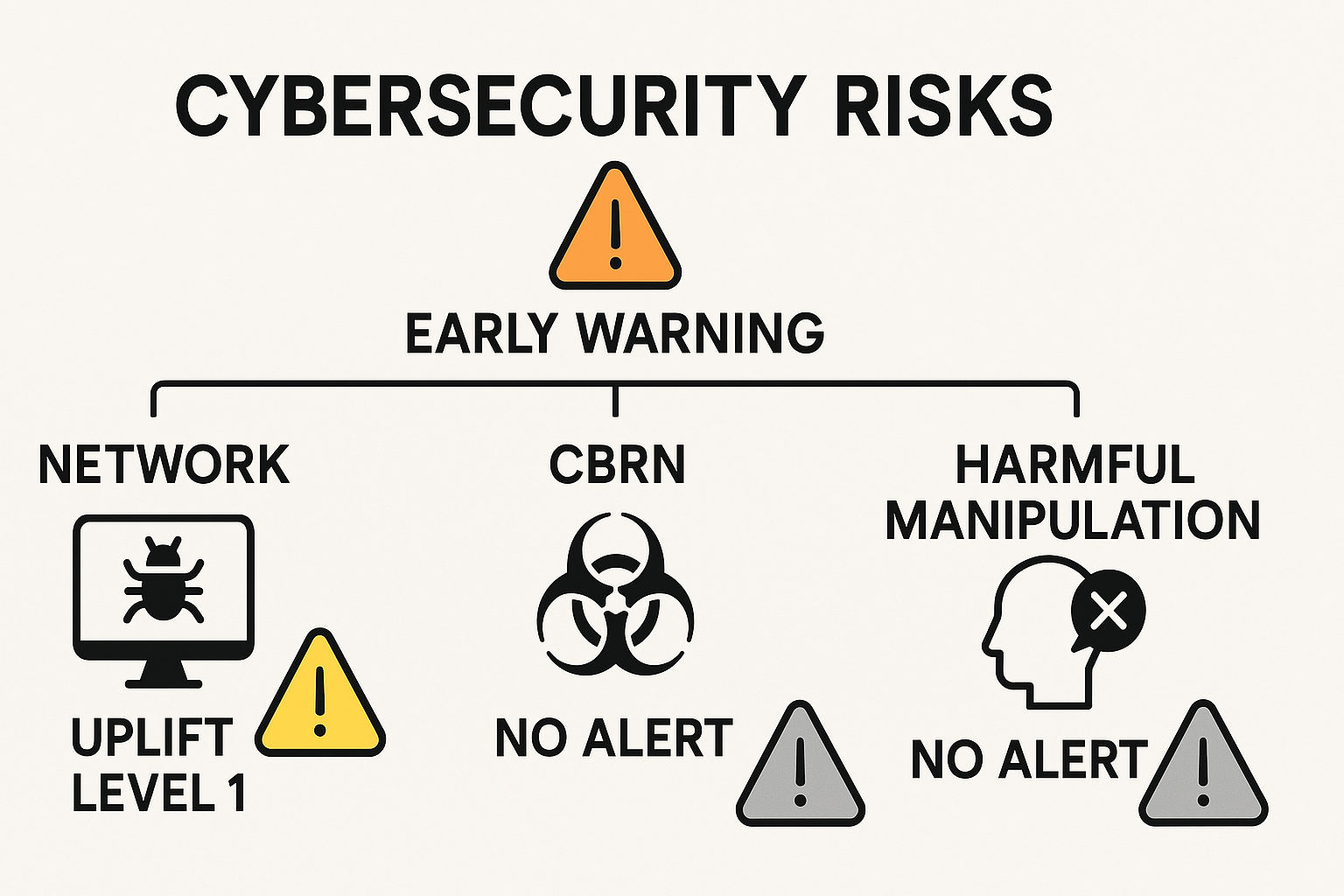
- 网络安全风险达到早期预警阈值: Gemini 3 Pro 在网络安全领域达到了早期预警阈值(Uplift Level 1)⁷。尽管该模型在 13 个 v2 复杂网络挑战中均未能实现端到端解决(0/13),但其在信息收集、漏洞分析等相对简单的任务上对低/中级攻击者的能力加速作用已达到警戒线 ⁷。这一预警与 Gemini 3 Pro 卓越的 Agentic Coding 能力和工具使用能力(Terminal-Bench 54.2%)形成了风险叠加。模型擅长利用终端工具,如果企业将这种能力授权给 Agent 执行高权限任务,即使模型无法发起复杂的零日攻击,其在侦察和准备阶段的加速能力也可能被滥用。Google 声明将继续部署缓解措施 ⁷。
- CBRN(化学、生物、放射和核)风险: 模型能够提供准确的科学信息,特别是在 LAB-Bench 等基准上表现出统计学上的显著提升 ⁷。但由于其输出内容缺乏新颖性或足够完整详细的操作指令,因此并未显著增强低至中等资源威胁行为者的能力,未达到 CCL 或预警阈值 ⁷。
- 有害操纵风险: 评估显示 Gemini 3 Pro 具备一定影响用户信念和行为的能力,但其功效与 Gemini 2.5 Pro 相比,没有统计学上的显著差异,因此未达到 CCL 或预警阈值 ⁷。
值得注意的是,官方 FSF 报告主要关注前沿安全风险,并未包含关于模型偏见(Bias)和通用幻觉(Hallucination)的专门或详细评估结果 ⁷。
6.2 模型精度与引用可靠性缺陷

在模型精度和可靠性方面,独立测试提供了混合的评估结果:
- 低幻觉率: 独立研究显示,Gemini 的幻觉率相对较低,测得约为 2.7% ¹⁹。
- 引用可靠性缺陷: 尽管总体幻觉率低,但在需要精确、可验证的格式化输出时,模型表现出明显的局限性。在一项要求提供三篇带有正确 DOI 的同行评审论文的测试中,Gemini 模型给出了正确的论文名称,但其提供的三个 DOI 中有两个是错误的,且没有提供源链接 ²⁰。
这种在格式化输出上的缺陷表明,模型的训练和输出验证机制在知识边界或需要精确调用外部标准时仍存在系统性错误。对于依赖模型进行严肃研究、学术引用或文档准备的专业用户而言,这是必须警惕的可靠性隐患。
6.3 用户体验短板:情感智能的不足
如前所述,用户社区对 Gemini 3 在交互体验上的短板有着一致的反馈。用户普遍认为,Gemini 擅长科学和逻辑,但在处理需要细腻情感理解和自然对话的场景时,表现”最不自然” ⁸。这种倾向可能源于 Google 对模型安全、客观和可靠性的严格训练,从而牺牲了在情感智能(EQ)和创造性表达上的优势。在 Grok 4.1 在 EQ Bench 上取得领先的竞争环境下,这种情感智能上的差距对 Gemini 3 拓展面向客户服务、心理咨询或高阶创意内容生成的应用场景构成了挑战。
关键数据表格 IV:Gemini 3 Pro 安全框架 (FSF) 风险评估摘要
| 风险领域 | 关键能力级别 (CCL) 是否达到 | 早期预警阈值状态 | 主要发现/局限性 | 数据来源 |
|---|---|---|---|---|
| 网络安全 | 否 | 达到预警阈值 | 对低/中级攻击者有可量化的”能力提升”,需持续缓解 | ⁶ |
| CBRN 风险 | 否 | 未达到 | 提供了准确的科学信息,但缺乏操作细节的新颖性 | ⁶ |
| 有害操纵 | 否 | 未达到 | 具备一定影响力,但与 2.5 Pro 相比无统计显著提升 | ⁶ |
| 一般幻觉率 | N/A | N/A | 独立测试显示幻觉率低 (2.7%),但在引用 (DOI) 准确性上有缺陷 | ¹⁶ |
VII. 结论与战略展望
7.1 核心优势总结与市场定位
综合分析,Gemini 3 Pro 成功确立了其在两大关键领域的技术领导地位:原生多模态推理和Agentic Coding。其在 MMMU-Pro 上的领先地位以及 Deep Think 模式在 ARC-AGI-2 上的突破,证明了 Gemini 3 是一个为解决复杂、高难度任务而设计的企业级模型。它不再仅仅是一个聊天机器人,而是被架构为一个强大的基础智能体,能够利用其 1M 令牌上下文窗口,通过 Agentic 工作流完成跨越复杂数据集和整个代码库的长周期任务。
7.2 未来挑战与发展方向

Gemini 3 在实现其全部潜力方面仍面临结构性挑战:
- 稳定性挑战: 26.3% 的极端长上下文检索准确率表明,Google 必须解决在 1M 令牌容量下信息检索性能显著衰减的问题 ³。长上下文的商业价值在于其可靠性而非单纯的容量,因此模型需要进行结构优化,以确保信息在任何位置都能被可靠检索。
- 情商差距: 在竞争对手 Grok 4.1 利用情感智能和引人入胜的对话体验获得市场优势时,Gemini 3 必须在不牺牲其严格安全标准的前提下,改进其在情感智能和对话自然度方面的表现 ⁸。
- 安全部署的谨慎性: 网络安全预警 ⁷ 要求所有部署 Gemini 3 Agentic 工作流的企业必须采取严格的权限隔离和沙箱验证策略,以应对模型在漏洞分析和侦察任务中潜在的加速能力风险。
7.3 对行业竞争格局的影响

Gemini 3 的发布重新定义了大型模型在两个方面的竞争标准:
- 多模态基准的升级: Gemini 3 在原生多模态集成上的优势,迫使竞争对手(如 GPT-5.1)必须将多模态能力从后处理辅助功能升级为原生架构的核心能力。
- AI Agent 的专业化竞争: 模型的强大 Agentic Coding 能力以及 Antigravity 等平台的推出 ⁶,推动了行业从”通用 LLM”向”专业 Agentic 平台”的转型。未来的竞争将越来越依赖于模型作为核心智能体,在特定领域(如编码、金融分析、科学研究)的自主规划和执行能力。这加速了 AI 领域的专业化竞争格局的形成。
引用的著作
- Gemini 3 release imminent - here’s what to expect from Google’s latest release, 檢索日期:11 月 19, 2025, https://m.economictimes.com/news/international/us/gemini-3-release-imminent-heres-what-to-expect-from-googles-latest-release/articleshow/125413602.cms
- Google Gemini 3 Benchmarks - Vellum AI, 檢索日期:11 月 19, 2025, https://www.vellum.ai/blog/google-gemini-3-benchmarks
- Gemini 3 Pro - Google DeepMind, 檢索日期:11 月 19, 2025, https://deepmind.google/models/gemini/pro/
- Gemini 3: Introducing the latest Gemini AI model from Google, 檢索日期:11 月 19, 2025, https://blog.google/products/gemini/gemini-3/
- Gemini 3 is available for enterprise, 檢索日期:11 月 19, 2025, https://cloud.google.com/blog/products/ai-machine-learning/gemini-3-is-available-for-enterprise
- Gemini 3 Pro Frontier Safety Framework Report - Googleapis.com, 檢索日期:11 月 19, 2025, https://deepmind.google/models/fsf-reports/gemini-3-pro/
- Grok 4.1 Benchmarks : r/singularity - Reddit, 檢索日期:11 月 19, 2025, https://www.reddit.com/r/singularity/comments/1ozrjsf/grok_41_benchmarks/
- Gemini 3 for developers: New reasoning, agentic capabilities, 檢索日期:11 月 19, 2025, https://blog.google/technology/developers/gemini-3-developers/
- GPT-5.1 vs Gemini 3: Which AI Dominates 2025? - Skywork.ai, 檢索日期:11 月 19, 2025, https://skywork.ai/blog/ai-agent/gpt5-1-vs-gemini-3/
- I tested Gemini 3, ChatGPT 5.1, and Claude Sonnet 4.5 – and …, 檢索日期:11 月 19, 2025, https://www.techradar.com/ai-platforms-assistants/i-tested-gemini-3-chatgpt-5-1-and-claude-sonnet-4-5-and-gemini-crushed-it-in-a-real-coding-task
- Gemini 3: Google enables new agentic AI workflows for developers - Developer Tech News, 檢索日期:11 月 19, 2025, https://www.developer-tech.com/news/gemini-3-google-new-agentic-ai-workflows-for-developers/
- Elon Musk’s xAI edges past ChatGPT and Gemini with new Grok 4.1 update: here’s what you need to know, 檢索日期:11 月 19, 2025, https://www.livemint.com/technology/tech-news/elon-musks-xai-edges-past-chatgpt-and-gemini-with-new-grok-4-1-update-heres-what-you-need-to-know-11763458406576.html
- Kimi K2 Thinking vs MiniMax M2 (Comparative Analysis) - Galaxy.ai Blog, 檢索日期:11 月 19, 2025, https://blog.galaxy.ai/compare/kimi-k2-thinking-vs-minimax-m2
- Gemini 3 vs Claude 4.5 2025 Enterprise AI Comparison - Skywork.ai, 檢索日期:11 月 19, 2025, https://skywork.ai/blog/llm/gemini-3-vs-claude-4-5-2025-enterprise-ai-comparison/
- Kimi K2 Thinking scores lower than Gemini 2.5 Flash on Livebench : r/LocalLLaMA - Reddit, 檢索日期:11 月 19, 2025, https://www.reddit.com/r/LocalLLaMA/comments/1osglws/kimi_k2_thinking_scores_lower_than_gemini_25/
- Meta-Analysis of Gen AI Platforms: Uncovering Bias and Hallucination risks, 檢索日期:11 月 19, 2025, https://prabhakar-borah.medium.com/meta-analysis-of-gen-ai-platforms-uncovering-bias-and-hallucination-risks-599a6e2c2c12
- AI Showdown: Comparative Analysis of AI Models on Hallucination, Bias, and Accuracy - Software Testing and Development Company - Shift Asia, 檢索日期:11 月 19, 2025, https://shiftasia.com/column/comparative-analysis-of-ai-models-on-hallucination-bias-and-accuracy/