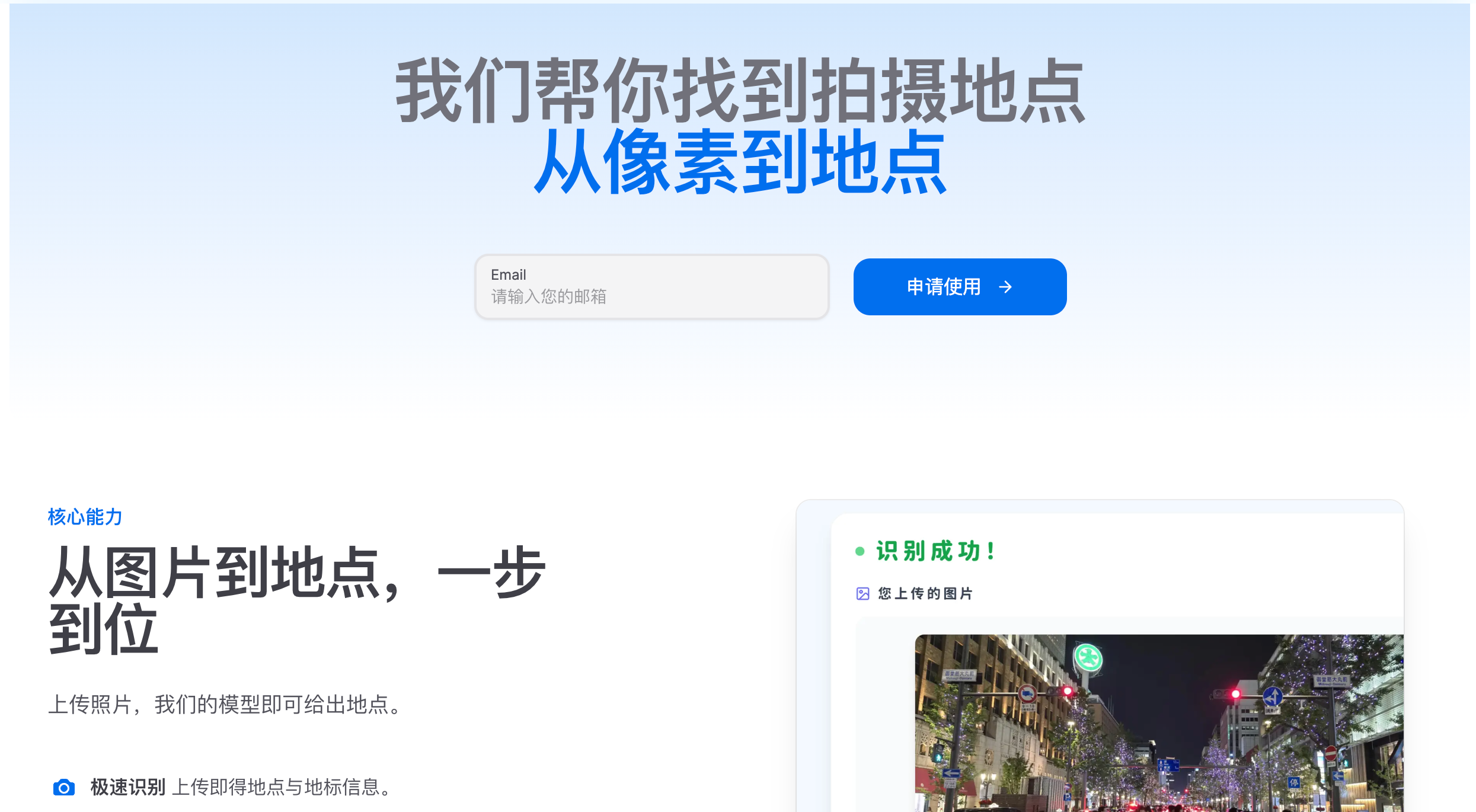
📋 产品概述
乐可寻 Locate-It 是一款基于人工智能的地点识别服务,通过分析图片内容来推测可能的地理位置。我们采用多模态 AI 模型结合网络检索技术,对图片中的视觉信息进行智能分析和推理,为用户提供地点参考信息。
🎯 核心功能
🌍 AI 视觉分析与推理
- 多模态 AI 识别:采用 BigModel GLM-4.5V 模型,分析图片中的视觉特征
- 智能推理机制:基于图像内容、建筑风格、自然景观等线索进行地点推测
- GPS 数据优先:当图片包含 EXIF GPS 数据时,优先使用精确坐标信息
- 概率性结果:提供基于 AI 分析的地点建议,而非绝对准确的位置信息
🎨 虚拟场景分析与原型探索
- 作品场景识别:识别动漫、游戏、影视剧中的虚拟场景
- 现实原型推测:基于视觉特征推测可能的现实取景地或灵感来源
- 创意推理:通过 AI 推理分析虚拟场景与现实地点的关联性
- 外部验证:利用网络搜索验证和补充识别结果
🗺️ 地点信息展示与地图可视化
- 交互式地图:在百度地图上展示推测的地点位置
- 坐标参考:提供地理坐标作为位置参考信息
- 地址解析:将坐标转换为可读的地址描述
- 可视化展示:直观的地图界面帮助用户理解位置信息
🔍 智能搜索与信息补充
- 网络检索:集成 Tavily API 搜索相关地点信息
- 信息提取:从搜索结果中提取有用的位置描述和背景资料
- 交叉验证:通过多源信息提升识别结果的可信度
- 背景补充:提供地点的相关背景信息和文化介绍
🎨 产品特色
🤖 双模式分析能力
- 现实场景分析:分析真实照片中的地点线索,推测可能位置
- 虚拟场景探索:处理二次元和影视内容,探索现实原型可能性
📱 友好的用户体验
- 简洁操作:拖拽或点击上传图片,即可开始分析
- 多格式支持:支持 JPG、PNG、WebP、HEIC 等常见格式
- 实时进度:展示分析进度,让用户了解处理状态
- 结果展示:清晰的分析结果展示,包括推理过程说明
🎯 智能化推理流程
- 多层次分析:从整体景观到具体细节的逐步分析
- 线索整合:综合视觉线索、GPS 数据、网络信息进行推理
- 概率评估:为识别结果提供置信度参考
- 透明化过程:展示 AI 的推理逻辑和判断依据
🎯 主要使用场景
🎮 动漫游戏文化探索
场景:看到动漫游戏中的美丽场景,想了解现实中的可能取景地
价值:发现虚拟作品与现实世界的连接,为「圣地巡礼」提供参考
🎬 影视拍摄地探寻
场景:观看影视剧时对某个场景产生兴趣,想了解拍摄地信息
价值:探索影视作品背后的真实地点,满足观众的好奇心
🏞️ 摄影创作参考
场景:摄影师寻找拍摄地点参考,分析优秀作品的地理位置
价值:为摄影创作提供地点灵感,帮助发现新的拍摄角度
🔬 技术原理说明
🧠 AI 分析机制
我们的系统采用多模态 AI 模型,通过以下步骤进行分析:
- 视觉特征提取:识别图片中的建筑、自然景观、人文特征
- 风格判断:分析建筑风格、植被特征、地形地貌等线索
- 地理位置推理:基于视觉线索和知识库推测可能的地区
- 网络验证:通过搜索相关信息验证和补充推测结果
📊 结果可信度
- GPS 数据:当图片包含精确 GPS 信息时,准确性最高
- AI 推测:基于视觉分析的地点推测,提供参考性建议
- 网络验证:通过多源信息交叉验证提升结果可信度
📈 产品特点
- AI 驱动:基于最新多模态 AI 技术的智能分析
- 推理导向:通过逻辑推理提供地点建议,而非简单匹配
- 虚实结合:同时支持现实场景和虚拟场景分析
- 用户体验:简洁直观的操作流程
- 信息丰富:提供地点背景信息和文化介绍
- 持续学习:AI 模型不断优化,提升分析能力
🚀 使用建议
- 提供线索:在分析时提供地区范围或作品名称等线索可提升效果
- 理解概率性:AI 分析结果仅供参考,实际地点可能存在差异
- 多角度验证:重要用途建议结合其他方式确认地点信息
- 探索发现:将产品视为探索工具,发现图片背后的有趣故事
乐可寻 Locate-It — 让 AI 帮您探索图片背后的地理故事 🌍🔍